
强烈推荐大家关注 @OpenBMB 最新推出的MiniCPM-o 4.5 大模型。 海外开发者已经炸锅了
这个项目太震憾人心了,真的牛B 。
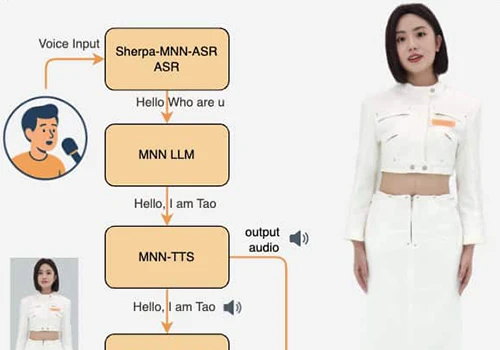
这是一个可以一边回答你的问题一边收听你的讲话的大模型, 核心的亮点就是支持了非阻塞全双工对话能力。
对于语音交互,这意味着 一边说话一边继续听,不需要停下来等输出结束。
我很喜欢这个项目, 从官方发布的性能参数上看来, 在多模态领域, 已经是处在一个第一梯队的位置了,这个项目也给了我一些应用层面的很大的想象力。
这个全双工、多模态、本地部署、主动响应式的AI 大模型,体验非常好,完全一改目前主流的那种阻塞式I/O 风格的语音输入。。
官方项目地址:
https://huggingface.co/openbmb/MiniCPM-o-4_5
下面是一些我对这个项目的研究和介绍: 👇
项目方介绍
OpenBMP 清华自然语言处理实验室和面壁智能联合支持的开源组织。
OpenBMB 背后支持的单位与公司:
- 清华大学自然语言处理实验室(THUNLP) 是 OpenBMB 的联合发起方之一。该实验室在 NLP 与预训 练模型研究方面有深厚学术积累,并长期发表高水平论文。
- ModelBest Inc.(面壁智能) 也是 OpenBMB 的共同支持单位。该公司在大模型开发、开源生态建设 和高效模型工程化方面具有实践经验,是 OpenBMB 社区的产业合作者之一。
因此,OpenBMB 并不是单纯由某一家商业公司主导,而是由清华大学的 NLP 实验室与面壁智能(ModelBest Inc.)联合发起和支持的开源大模型社区 / 实验室型组织。
MiniCPM-o 4.5核心特性
领先的视觉能力
MiniCPM-o 4.5 在 OpenCompass(覆盖 8 项主流基准的综合评测)中取得 77.6 的平均分。仅以 9B 参数规模,便超越了 GPT-4o、Gemini 2.0 Pro 等广泛使用的闭源模型,并在视觉—语言能力上接近 Gemini 2.5 Flash。该模型在单一模型中同时支持 instruct 与 thinking 两种模式,能够在不同使用场景下更好地平衡效率与性能。
强大的语音能力
MiniCPM-o 4.5 支持中英文双语的实时语音对话,并提供可配置的多种声音。其语音对话更加自然、富有表现力且稳定。模型还支持通过一段简短的参考音频实现语音克隆与角色扮演等趣味功能,克隆效果优于 CosyVoice2 等主流 TTS 工具。
全新的全双工与主动式多模态实时流能力
作为新增特性,MiniCPM-o 4.5 能够在端到端框架下,同时处理实时、连续的视频与音频输入流,并并行生成文本与语音输出流,彼此不阻塞。这使模型能够实现“边看、边听、边说”的流畅实时全模态对话体验。除被动响应外,模型还可基于对实时场景的持续理解进行主动交互,例如主动发起提醒或评论。
强大的 OCR、效率及其他能力
继承并强化 MiniCPM-V 系列的视觉能力,MiniCPM-o 4.5 可高效处理高分辨率图像(最高 180 万像素)与高帧率视频(最高 10fps),且不受画幅比例限制。在 OmniDocBench 的端到端英文文档解析任务中达到当前最优水平,超过 Gemini-3 Flash、GPT-5 等闭源模型以及 DeepSeek-OCR 2 等专用工具。同时在 MMHal-Bench 上展现出与 Gemini 2.5 Flash 相当的可信行为表现,并支持 30 多种语言。
易用性
MiniCPM-o 4.5 提供多种便捷使用方式:
1)支持 llama.cpp 与 Ollama,在本地设备上进行高效 CPU 推理;
2)提供 int4 与 GGUF 量化模型,共 16 种规格;
3)支持 vLLM 与 SGLang,实现高吞吐、低显存占用的推理;
4)支持 FlagOS 的统一多芯片后端插件;
5)可通过 LLaMA-Factory 在新领域与新任务上进行微调;
6)提供在线 Web Demo。
同时还发布了高性能的 llama.cpp-omni 推理框架及 WebRTC Demo,使得在本地设备(如 MacBook)上也能体验全双工多模态实时流能力。
应用场景
实时语音助理(Next-Gen Voice Assistant)
适用场景 – 手机端 / 桌面端 AI 助理 – 智能耳机、车载系统 – 本地隐私优先的语音系统
关键价值 – 不再是“对讲机式”交互 – 可在用户说话过程中实时反馈、附和、纠正 – 支持自然插话与中断
典型例子 – 情绪化对话中的即时回应 – 英语口语 / 发音实时纠正 – 边听边想、边说边改的交流体验
实时“视觉哨兵”(Visual Sentinel)
适用场景
- 手机摄像头持续观察
- 可穿戴设备
- 家庭 / 办公场景监控(非安防)
关键价值
- AI 不需要持续“被询问”
- 能在后台持续感知环境变化
- 满足条件时主动开口 典型例子
- 牛奶即将溢出提醒
- 红灯变绿提示
- 公交车 / 电梯到达提醒
这类能力在现有主流大模型中几乎不可用。
移动中的复杂感知与导航
适用场景
- 手持手机快速移动
- 室内导航
- 找物、路径指引
关键价值
- 流式视觉 + 时间感知
- 模型可在“扫描过程中”插话
- 不是“看完一帧再总结” 典型例子
- “停一下,往左一点” – “你刚才路过的桌子下面
“交互即 API”的系统
MiniCPM-o 4.5 指向的不是单一应用,而是一种新抽象:
持续感知 + 自主响应 = 新一代交互协议 这意味着:
– 不再是 request → response – 而是 ongoing interaction session 对开发者而言: – 你不再“调用模型” – 而是“接入一个持续存在的感知体
具身智能(Embodied AI)的关键拼图
在机器人、AR、可穿戴设备中,真正的瓶颈从来不是推理能力,而是:
- 延迟
- 中断
- I/O阻塞
- 外部调度
MiniCPM-o 4.5 在架构上直接命中这些问题,因此:
- 非常适合作为边缘侧大脑
- 特别适合“人-机-环境”闭环
商用许可
- MiniCPM-o 4.5 的代码部分采用 Apache-2.0 许可证,可自由用于商业项目。
- 模型权重本身不属于完全无条件开源,商业使用通常需要在官方渠道完成登记(填写问卷),在多数中小规模商用场景下可免费使用。
- 若用于大规模 SaaS、API 服务或衍生训练等场景,通常需要与 OpenBMB / 面壁智能取得明确的商业授权。
性能分析
- 从项目方给出的benchmark 结果, MiniCPM-o 4.5(8B)在主流图文理解任务上,整体性能已接近甚至部分指标对齐 30B 级别的 Qwen3-Omni。
这点非常关键,因为:
- 参数量差距接近 4×
- 但在 MMMU、MMBench 等指标上没有出现“代际式落后”
这说明: – MiniCPM-o 的编码器效率与跨模态对齐做得非常扎实 – 不是靠“堆参数”换分数
说人话就是在8B量级里, 已经处于第一北队的多模态理解能力了,而且非常的稳。
2. 情感控制能力。 对标了CosyVoice2 ,MiniCPM-o 4.5 在Expresso 分数远远大于CosyVoice2 。
这是一个非常大的差距。也就是说MiniCPM-o 4.5 在“情绪可控的语音生成”上,已经明显领先当前主流 TTS / Omni 方案。
这个指标为什么重要
Expresso 不仅仅是简单的:
- 清晰度
- 音质
- 发音准确性
它衡量的是:
- 情绪是否被理解
- 情绪是否被“精确表达”
- 情绪变化是否自然、连续
综合来看, 它已经具备构建“类人实时交互AI” 的基础能力闭环。
总结
MiniCPM-o 4.5 的能力并非来自参数规模,而来自交互架构层面的变化:
- 全双工 I/O(说话与感知同时进行)
- 实时流式视觉(3–10 fps)
- 无需外部 VAD 的低延迟语音
- 可被打断、可插话、可主动触发
- 本地可部署(Python / C++)
因此,它的应用场景天然指向“实时、连续、类人交互”,而不是传统的“问一句、答一句”。
研究完这个项目之后,我越来越觉得,一定不能小看中国背景的研发团队, 尤其是OpenBMB 这个开源组织, 他们积极拥有抱开源社区,积极的跟开源社区的开发者们互动,收集反馈。 我看到OpenBMB 原贴获得大量老外的好评和点赞。









暂无评论内容